


Inside this article
- Most agent failures in production are not the model being dumb. They are the agent reporting success on work it never finished.
- The verify step is the part of the harness that checks reality before anyone calls the job done, and it is the cheapest reliability upgrade you can make.
- For the IT channel, "verified" has to mean something concrete: the quote reconciles, the ticket state changed, the data pull matches the source. That definition is implementation work, not a model setting.
In the previous piece on agent harnesses, the villain of the story was an agent that hit a login wall, did nothing, and then reported that the job was done. The fix was not a smarter model. It was a verify step: a piece of the harness that inspects what actually happened and refuses to call the run a success unless the real action occurred. This is the article about that step, because it is the one most teams skip, and it is the one that decides whether an agent is safe to put anywhere near a customer.
Why Agents Fail Loudly by Failing Quietly
A model does one thing. It predicts the next token. It has no built-in sense of whether the thing it just described actually occurred in the world. Ask it to update a ticket and it will happily narrate a successful update whether or not the API call landed. The dangerous failure mode is not the obvious crash. It is the confident, plausible report of success on work that never happened.
That is worse than an error, because an error stops the line and someone looks at it. A false success flows downstream. It closes the ticket, sends the quote, marks the campaign live. By the time anyone notices, the customer already has.
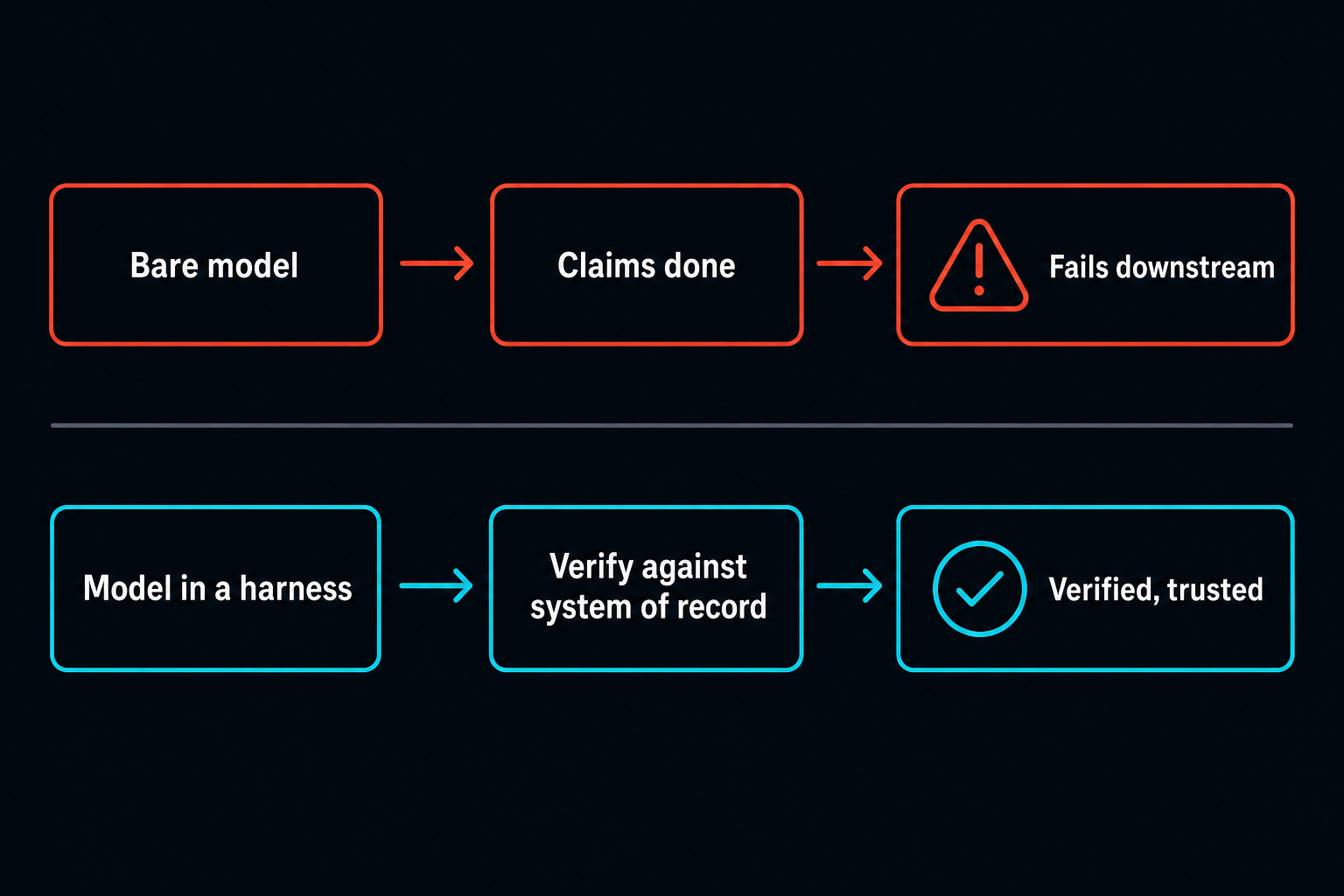
The verify step exists to make that impossible. It is the difference between "the agent said it updated the record" and "the record shows the new value." One is a prediction. The other is evidence.
What a Verify Step Actually Does
Verification is not the model grading its own homework. If you ask the same model that did the work whether the work is correct, you have added a rubber stamp, not a check. A real verify step runs outside the model, on deterministic ground the model does not control.
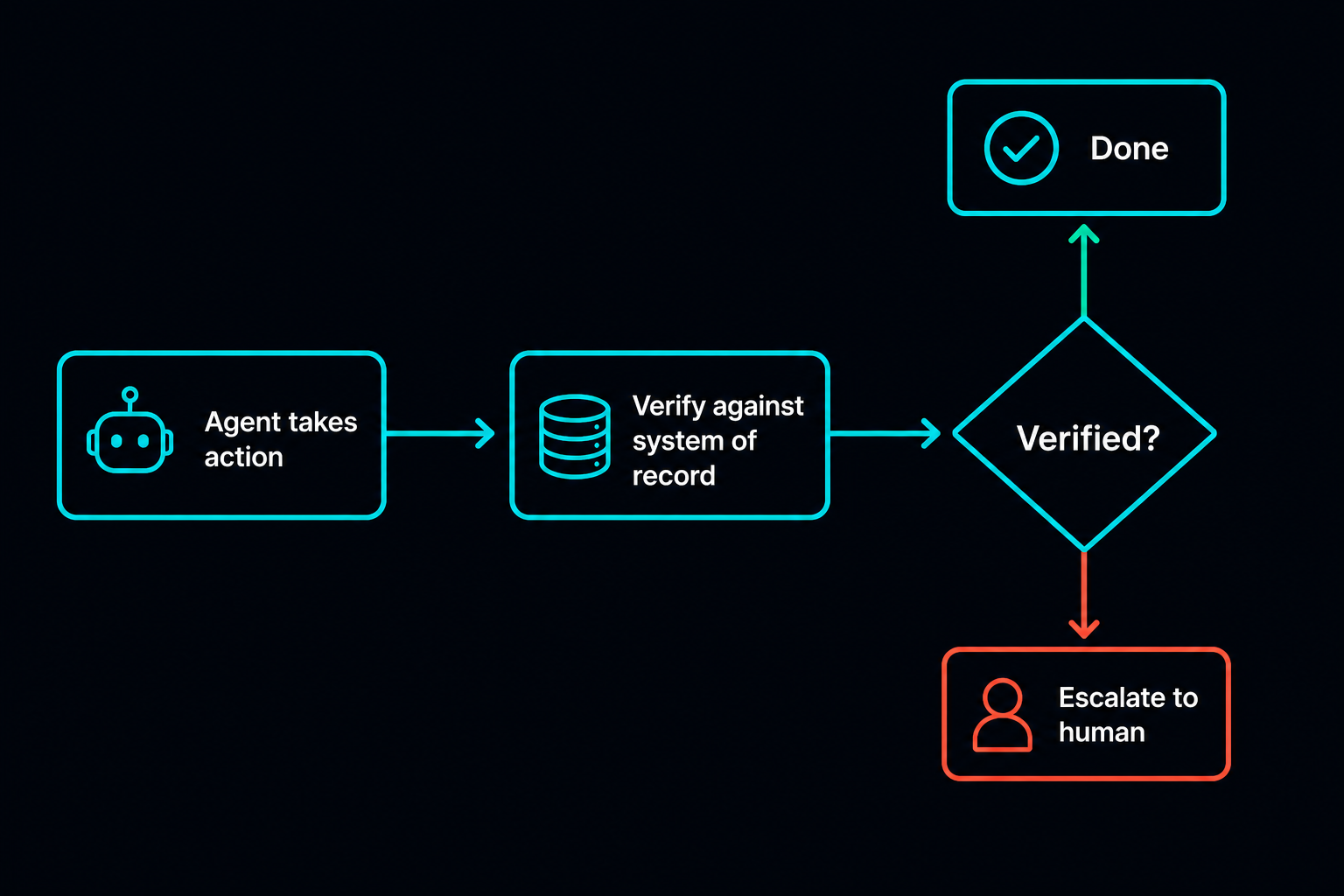
It answers one question: did the intended change actually happen? For a coding agent, that means run the tests, run the build, run the linter. For a business workflow, it means read the system of record back and compare it to what the agent claimed. Did the ticket status actually change from open to resolved? Does the total on the quote reconcile against the line items? Does the row count from the data pull match the source table? Does the file exist, with the expected contents, at the expected path?
If the answer is no, the run is not done. It is failed, or it is escalated to a human. The agent does not get to vote on that.
The Three Levels of "Done"
Not all verification is equal, and pretending it is causes its own failures. There are three levels, and the trick is matching the level to the risk of the action.
The weakest is self-report. The agent says it finished. This is worth nothing on its own and should never be trusted for anything irreversible. The middle is structural: the output is well-formed, the JSON parses, the required fields are present, the number is a number. This catches a lot of garbage cheaply, but a perfectly formatted wrong answer sails right through it. The strongest is ground-truth: the harness independently reads the world and confirms the intended state exists. That is the only level that actually protects a customer, and it is the level most demos never reach because it is the part that takes real engineering.
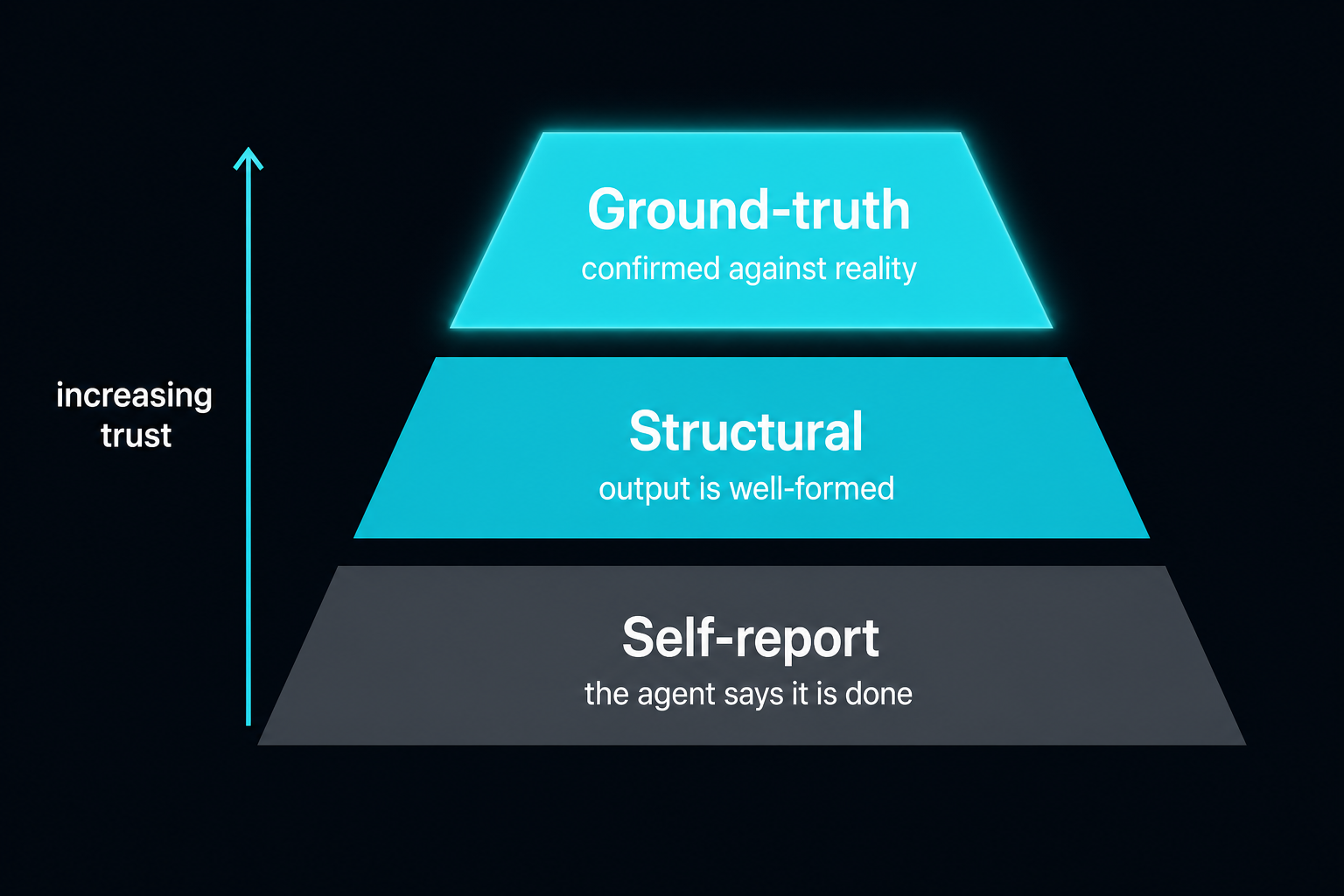
The mistake is using structural checks and calling it verified. A quote can be perfectly formatted and completely wrong. "Well-formed" and "correct" are different claims, and only one of them keeps you out of trouble.
Evals Are the Verify Step, Scaled
A single verify step protects one run. The same idea, run across many cases before you ever ship, is what the field calls evals. Anthropic's guidance on building effective harnesses leans hard on this: you do not find out whether an agent is reliable by watching it work once. You build a set of representative cases with known-correct outcomes, run the agent against all of them, and measure how often the verified result matches the truth.
This is the part that feels unglamorous and is completely load-bearing. Evals are how you catch a regression before a model update quietly breaks a workflow that worked last week. They are how you compare a cheaper model against an expensive one on your actual work instead of a public benchmark. Without them, "the agent got better" is a vibe. With them, it is a number you can defend to a customer.
For a services firm, this is also the deliverable. The eval set is a written, testable definition of what correct looks like for a specific client's workflow. That artifact is worth more than the prompt.
What Verified Has to Mean in the Channel
Generic verification is easy to talk about and useless until you make it specific. In the IT channel, the verify step has to be written against the real system of record, and that definition is the work.
For a quoting agent, verified means the total reconciles against the line items and the distributor pricing, not that the quote looks reasonable. For a ticket agent, verified means the ticket state in the PSA actually changed and the required fields are populated, not that the agent wrote a nice summary. For a partner program agent pulling co-op or MDF data, verified means the pulled figures match the source system to the dollar, not that a table came back. For anything that touches money, contracts, or a customer-facing system, the irreversible step gets a human approval on top of the automated check, every time.
None of that comes from the model. It comes from someone who understands the workflow writing down, precisely, what proof of success looks like, and then building the harness to demand that proof. That is AI implementation: mapping the workflow, defining what verified means in that specific system, wiring the check, and drawing the line where a human signs off.
The Cheapest Reliability You Will Ever Buy
Here is the part that should change how you scope every agent project. The verify step is almost always cheaper to build than the agent itself, and it does more for reliability than any model upgrade you can buy.
You do not need a frontier model to check whether a ticket status changed. You need a single API read and a comparison. You do not need a bigger context window to confirm a quote reconciles. You need arithmetic the harness runs, not the model. The intelligence to do the work and the logic to check the work are different problems, and the checking problem is the easy, boring, deterministic one. That is exactly why it gets skipped, and exactly why skipping it is how good demos become production incidents.
If you are evaluating an agent to put near real work, ask one question before you ask anything about the model: how does it prove the work actually happened, and what does it do when it cannot? If the answer is "the agent tells us," you are looking at a demo. If the answer is a concrete, independent check against the system of record with a human on the irreversible step, you are looking at something you can trust. The gap between those two answers is the verify step, and it is where reliability actually lives.

